À l’ère de l’essor technologique, nos systèmes deviennent de plus en plus complexes et interconnectés. Mais comment s’assurer qu’une infrastructure moderne reste performante et fiable en toutes circonstances ? Les entreprises, grandes et petites, adoptent des solutions innovantes qui révolutionnent leur manière de gérer les applications. Saviez-vous que certaines technologies permettent de surveiller et d’optimiser ces systèmes en temps réel ?
Imaginez une plateforme où chaque application, chaque microservice s’organise harmonieusement, même sous une forte charge. Comprendre ces outils peut paraître difficile au premier abord, mais démystifier leur fonctionnement ouvre la voie à des opportunités incroyables, que ce soit pour déployer efficacement, résoudre des problèmes ou encore éviter les défaillances. Plongeons ensemble dans cette approche révolutionnaire au service d’une gestion efficace des infrastructures.
Pourquoi surveiller vos clusters avec soin est essentiel
La réussite de la gestion des conteneurs repose sur une supervision efficace. Vos environnements orchestrés demandent une attention particulière pour garantir une disponibilité continue et une résolution rapide des problèmes. Un suivi rigoureux aide à maintenir les performances des services tout en anticipant d’éventuels dysfonctionnements. Cela est particulièrement vrai lorsque ces systèmes supportent des applications critiques.
Prenez l’exemple d’une entreprise qui déploie une plateforme e-commerce. Si un service mal configuré consomme excessivement des ressources, il risque de perturber d’autres éléments de l’architecture. En surveillant activement ces usages, vous identifiez les écarts et ajustez les paramètres avant que l’impact ne soit ressenti par les utilisateurs.
Centrer les données pour une analyse simplifiée
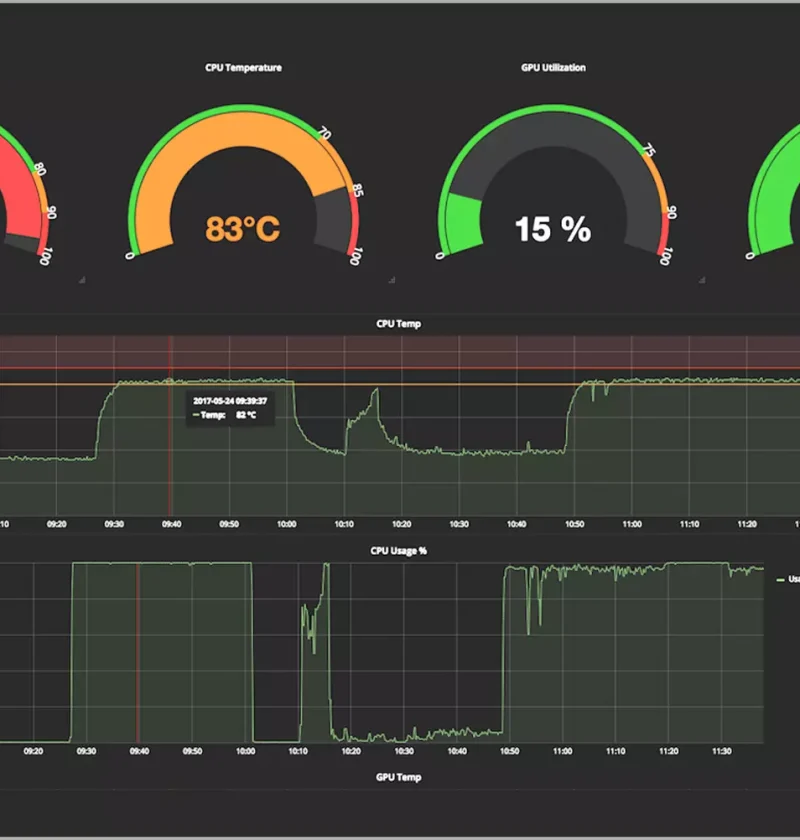
Avec des systèmes complexes, la dispersion des informations peut compliquer la prise de décision. Disposer d’un tableau de bord unique regroupant toutes les métriques vous permet de mieux comprendre l’état de vos infrastructures. Par exemple, si un composant montre une utilisation anormalement élevée du CPU, ce tableau vous alerte, facilitant ainsi une intervention rapide.
Les solutions existantes permettent souvent d’intégrer des visualisations en temps réel des métriques clés. Cela inclut l’utilisation des ressources, l’état des pods ou encore les délais de réponse des services. Ces données sont collectées et organisées pour offrir un aperçu précis de l’ensemble de l’environnement.
Priorité à l’automatisation des actions correctives
En automatisant certaines réponses aux alertes, vous minimisez les interruptions tout en réduisant le besoin d’interventions manuelles. Par exemple, si un nœud montre des signes de surcharge, une politique prédéfinie peut initier automatiquement le rééquilibrage des charges ou le déploiement de nouveaux pods. Cette approche garantit une continuité des services et améliore considérablement l’efficacité opérationnelle.
Une supervision optimale s’appuie sur des outils adaptés et des stratégies réfléchies qui vous aident à anticiper les défis liés à des infrastructures dynamiques.
Les outils indispensables pour superviser vos clusters
Superviser des environnements contenant des conteneurs devient plus simple avec les outils adéquats. Ces solutions modernes intègrent des fonctionnalités avancées offrant une visibilité totale sur la santé de vos systèmes déployés. Elles permettent de réagir rapidement face aux incidents, d’analyser les performances et d’optimiser l’utilisation des ressources pour garantir une infrastructure stable et efficace.
Les tableaux de bord dynamiques pour une vue d’ensemble
Des outils tels que Prometheus et Grafana permettent de concevoir des tableaux de bord personnalisés donnant une vue synthétique des métriques clé, comme l’usage du processeur, la consommation de mémoire ou encore la latence des services. Par exemple, un graphique en temps réel peut indiquer une surcharge sur un pod, ce qui permet à l’administrateur d’ajuster les ressources avant qu’un incident n’impacte les utilisateurs.
Ces tableaux de bord offrent plus qu’une simple visualisation des données. Grâce à leur système d’alerte configurable basé sur des seuils, ils garantissent une réactivité accrue face aux anomalies, qu’il s’agisse de surcharges ou d’événements inhabituels dans le système.
La gestion des logs pour une analyse approfondie
Analyser les journaux est une étape primordiale dans tout processus de supervision. Avec des outils comme Fluentd ou Elasticsearch, les journaux produits par vos conteneurs sont collectés, centralisés et triés de manière efficace. Cela permet, par exemple, de détecter des erreurs récurrentes et de déployer rapidement des correctifs adaptés.
Cette gestion centralisée offre une traçabilité optimale et accélère le diagnostic en cas de défaillance critique, simplifiant grandement l’identification de la cause des problèmes et améliorant la résolution proactive des incidents.
Les outils avancés pour gérer la surveillance des conteneurs
Pour assurer une gestion optimale de vos conteneurs, recourir à des outils spécialisés de surveillance est crucial. Ces technologies garantissent non seulement la stabilité, mais aussi les performances de votre infrastructure, procurant ainsi une vision globale sur vos ressources et leur fonctionnement.
Des solutions comme Prometheus pour collecter des métriques
Prometheus est l’un des outils les plus utilisés dans cet écosystème. Il s’intègre parfaitement aux environnements conteneurisés et collecte des métriques en temps réel sur les divers services et conteneurs. Cela comprend des données clés telles que le taux d’utilisation du processeur, la consommation de mémoire et l’état des nœuds.
Grâce à sa compatibilité avec des outils de visualisation tels que Grafana, l’interprétation des résultats devient plus intuitive. Avec des tableaux de bord personnalisables, les anomalies ou surcharges de ressources sont identifiées rapidement, permettant de réagir efficacement pour garantir la continuité des services.
Les solutions centralisées pour simplifier l’analyse
Des plateformes comme Datadog offrent une vision unifiée de l’ensemble de votre infrastructure. Elles surveillent non seulement les conteneurs, mais aussi les réseaux et applications liés, facilitant la compréhension des interactions complexes.
En repérant automatiquement les erreurs possibles dans les configurations ou les dépendances, ces outils aident à corriger les problèmes avant qu’ils n’affectent les utilisateurs. Leur prise en main intuitive les rend judicieux pour toutes les équipes, qu’elles soient débutantes ou expérimentées.
Optimiser vos performances grâce à l’automatisation
L’intégration d’outils d’automatisation permet de gagner en efficacité et de réduire les marges d’erreur. Par exemple, Kubernetes Metrics Server surveille en continu les ressources et ajuste leur utilisation de manière automatisée, garantissant ainsi une gestion optimale sans effort supplémentaire.
Ces solutions minimisent les risques d’incidents tout en maintenant un service de grande qualité. Elles constituent une base fiable pour une orchestration plus performante et fluide.
Maîtriser la surveillance de vos infrastructures conteneurisées est indispensable pour assurer des performances de haut niveau. Les outils modernes permettent d’analyser vos ressources, de prévenir les anomalies et de réagir efficacement aux défis techniques. En adoptant ces innovations, vous améliorez la disponibilité de vos services tout en réduisant les risques de panne.
Investir dans des solutions avancées permet de mieux gérer la complexité des environnements dynamiques et de maximiser l’efficience de vos déploiements. Que vous cherchiez une gestion proactive, des tableaux de bord clairs ou une automatisation optimale, des outils adaptés sont à votre portée. Ne laissez pas un problème surgir pour agir : commencez dès aujourd’hui à optimiser la supervision de vos systèmes pour assurer la satisfaction de vos utilisateurs.
Explorez dès maintenant comment ces technologies peuvent révolutionner la gestion de vos conteneurs. Contactez-nous pour plus d’informations ou pour déployer les solutions les mieux adaptées à vos exigences spécifiques.
FAQ : Tout savoir sur la supervision des clusters
Comment identifier rapidement les anomalies dans un environnement conteneurisé ?
Pour détecter les écarts anormaux, il est crucial d’utiliser des tableaux de bord centralisés comme ceux proposés par Grafana ou Datadog. Ces outils analysent les métriques en temps réel et déclenchent des alertes automatisées lorsque des seuils critiques sont atteints, par exemple une surcharge de processeur ou une augmentation de la latence d’une application. Cela vous permet de réagir avant que les utilisateurs ne soient impactés.
Pourquoi l’analyse des journaux d’événements est-elle essentielle ?
Les journaux d’événements contiennent des informations détaillées sur chaque action ou incident au sein des clusters. En les centralisant avec des solutions comme Fluentd ou Elasticsearch, vous obtenez une traçabilité complète. Ce processus vous aide à identifier les erreurs récurrentes, les pannes potentielles et les comportements inhabituels de vos systèmes, facilitant ainsi leur correction.
Quelles actions peuvent être automatisées pour gérer une surcharge ?
Dans des infrastructures dynamiques, des outils comme Kubernetes permettent de configurer des réactions prédéfinies aux hausses de charge. Par exemple, il est possible d’automatiser le déploiement de pods supplémentaires ou de répartir la charge sur plusieurs nœuds pour maintenir la stabilité des services. Ces automatisations réduisent les risques d’interruption et assurent une gestion fluide.
Quels indicateurs surveiller pour maintenir une infrastructure stable ?
Un suivi rigoureux des métriques clés garantit la robustesse des environnements orchestrés. Ces indicateurs incluent la consommation de CPU, la mémoire disponible, le nombre de pods actifs ou encore la latence réseau. En combinant ces données dans une vue unifiée, vous identifiez rapidement les besoins de ressources ou les anomalies pouvant perturber vos services critiques.